Streaming Twitter data
Intro
This repository contains Python scripts that enable the processing of real-time Twitter data using Kafka and MongoDB. The scripts are designed to fetch data from the Twitter API, filter the data based on specific criteria, and store the filtered data into a MongoDB database.
In my professional experience, I’ve had the opportunity to work with batch processes most 99% part of my time. I’ve been reserarching and wondering to know this new face of development that is the Streaming pipelines. Leveraging that, I created this small solution to achieve that objective and see the flow.
Technical solution
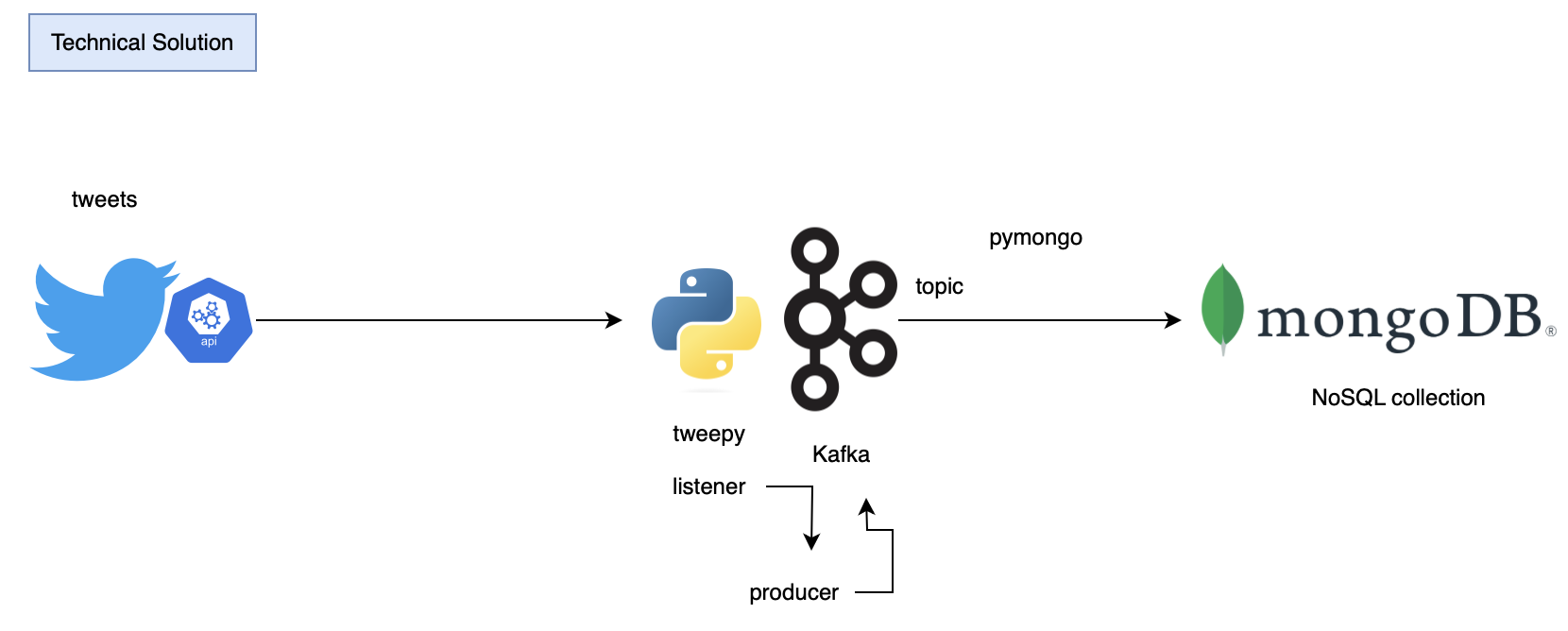
Requirements
To use these scripts, you will need the following:
- API Key Twitter for developer (free tier)
- Python 3.x
- tweepy package: This is a Python wrapper for the Twitter API.
- pymongo package: This is a Python driver for MongoDB.
- kafka-python package: This is a Python client for Apache Kafka.
- json package: This is a Python client for JSON.
Docker
This is our environment setup - managed by Docker compose file:

Lenses/Kafka
When the Docker goes up, verify the Kafka looking into the Lenses Web UI:
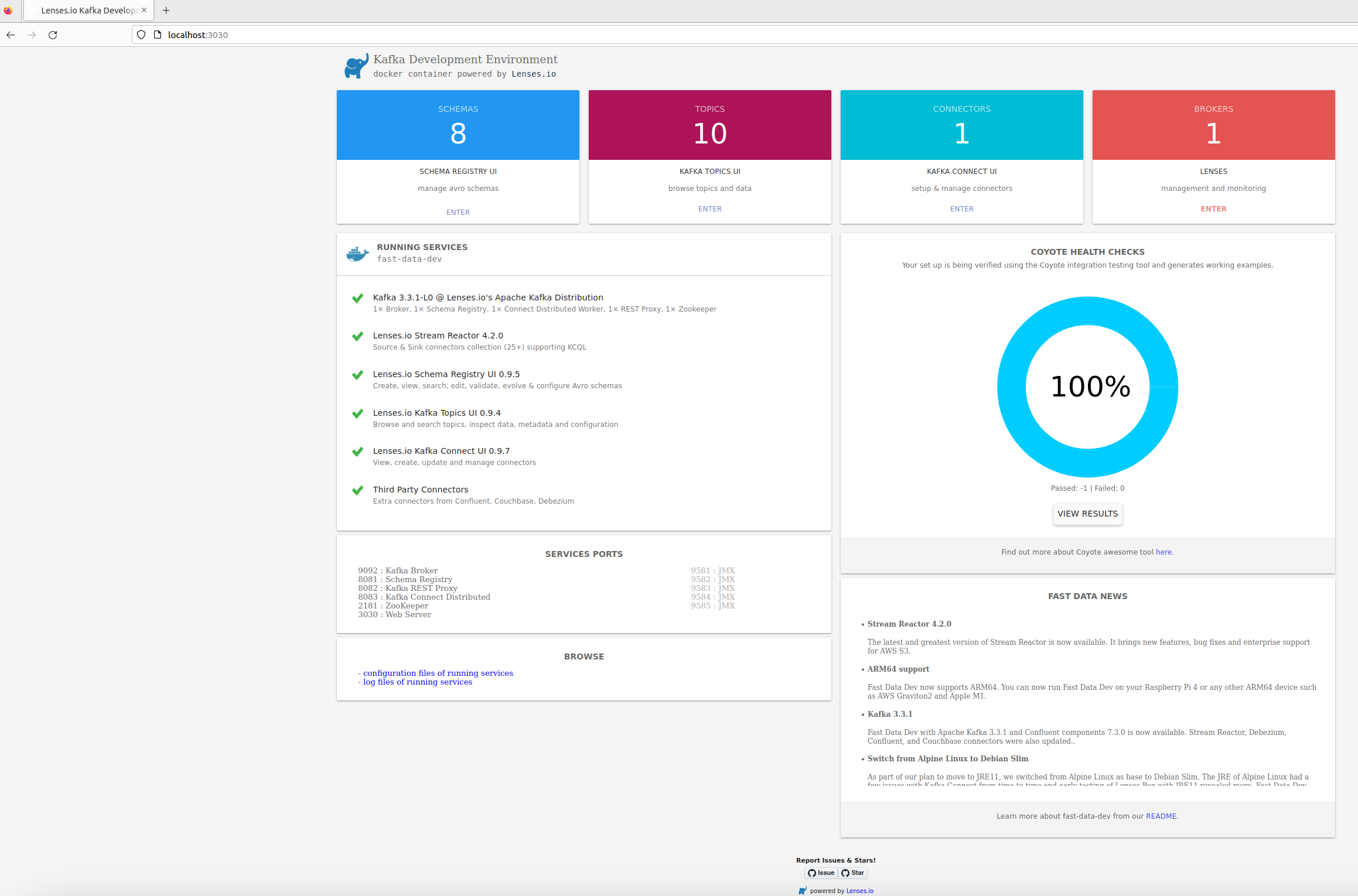
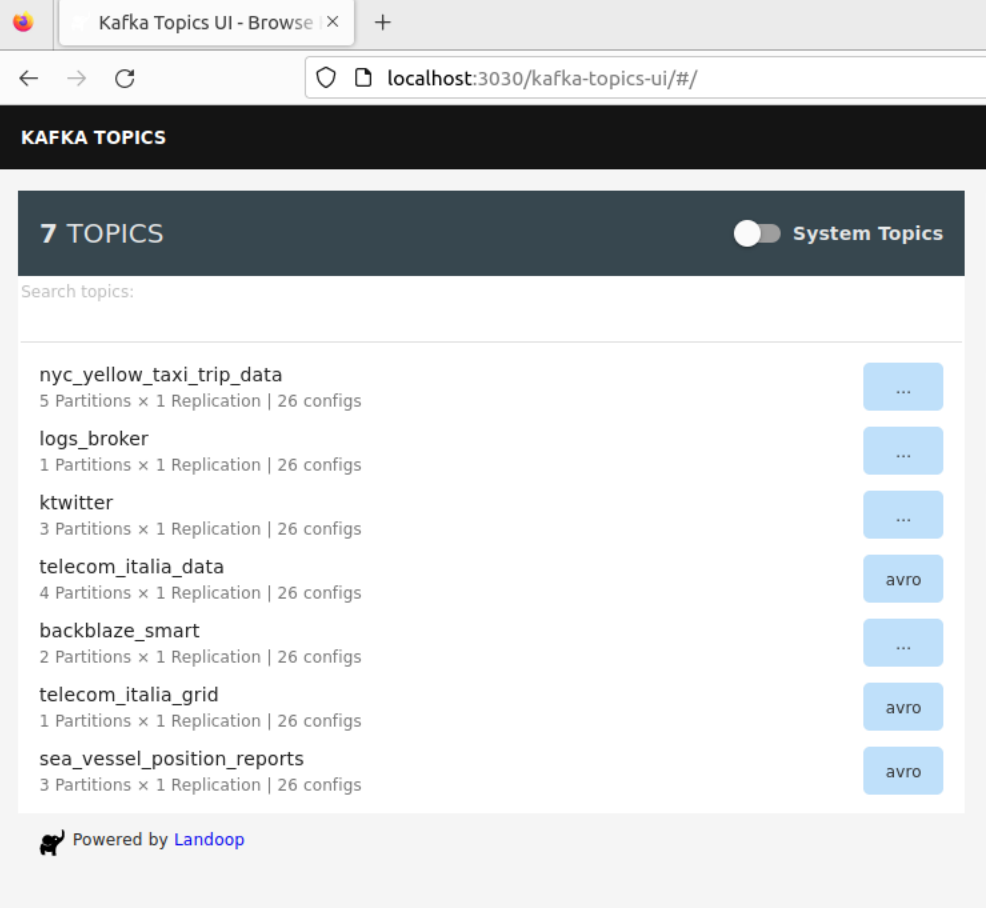
- After that, I created the topic into the Kafka service - the name was “ktwitter”.
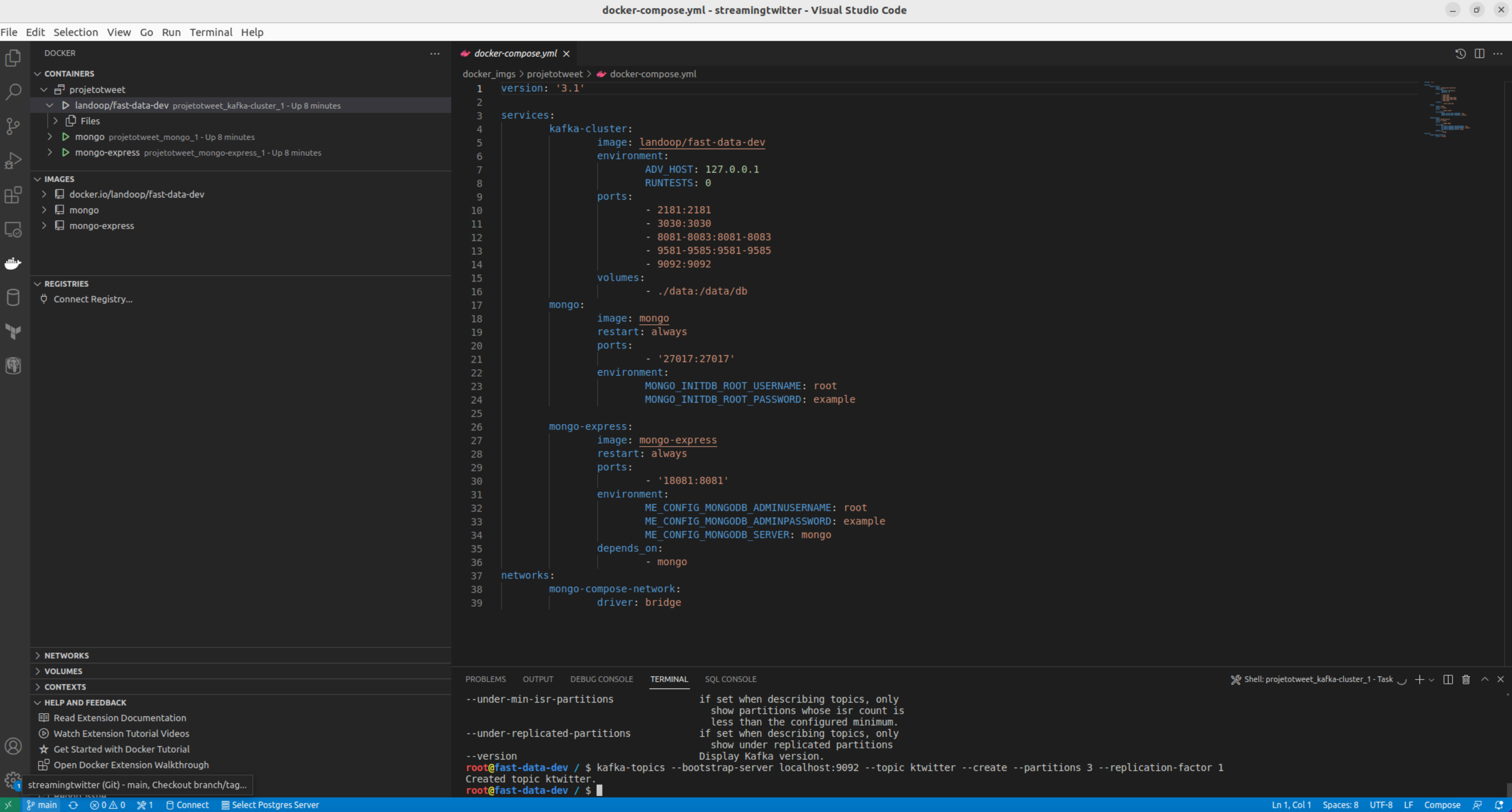
- Taking a look into the lenses if the topic was created successfuly:

Outcome
- Once the setup process is finished, execute the provided script below to observe the outcomes within MongoDB.
- Modify the keywords or conduct a comparative analysis between them.
- Within the NoSQL Database, you can retrieve the data for the purpose of conducting analysis, generating statistics, or facilitating consumption through an alternative reporting tool.
More
- GitHub Repo here.