Pipelines with Spark Databricks and Report
This pipeline provides a comprehensive demonstration of the end-to-end process, excluding the initial data source integration. It encompasses best practices in data modeling (star schema), leverages the power of Spark for distributed computation, and ultimately delivers a compelling outcome in the form of a detailed Power BI report.
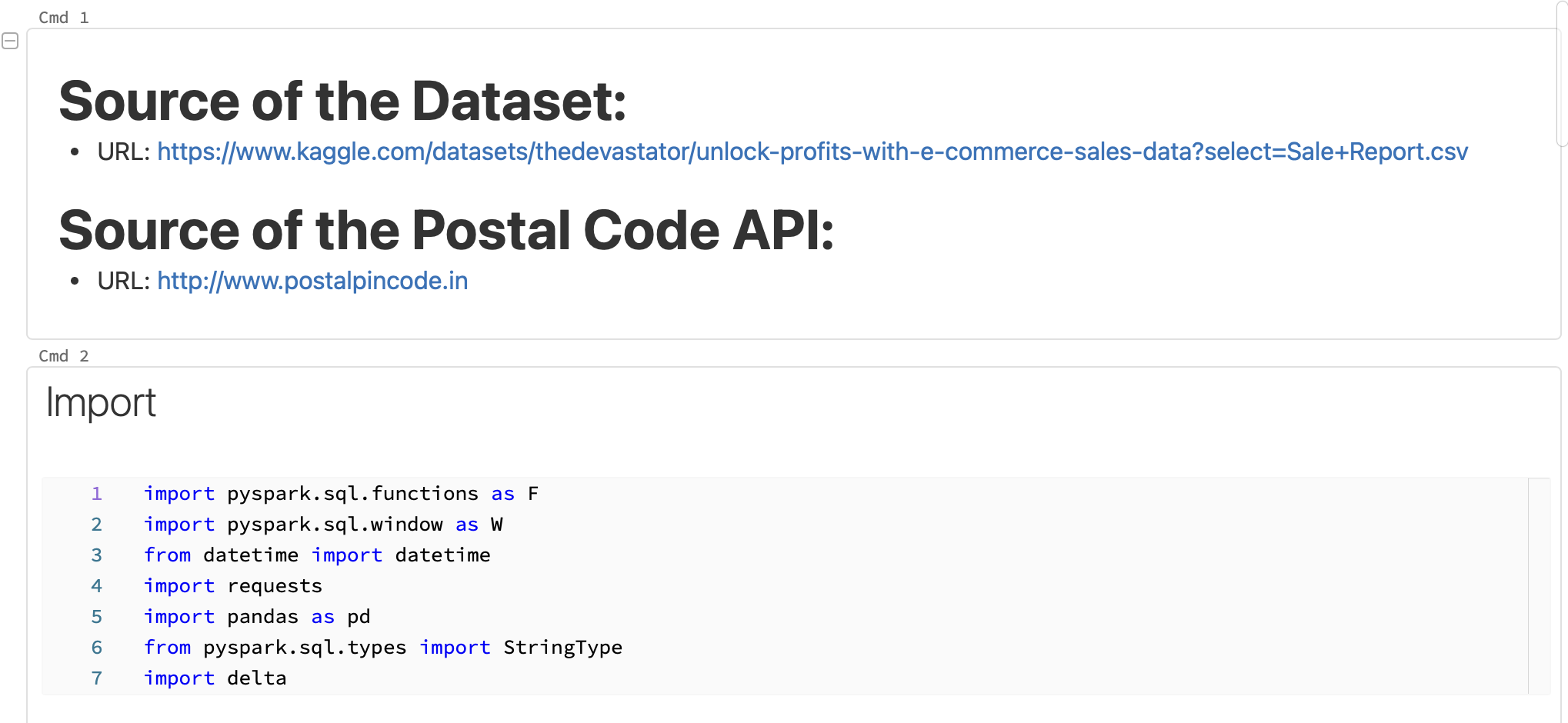
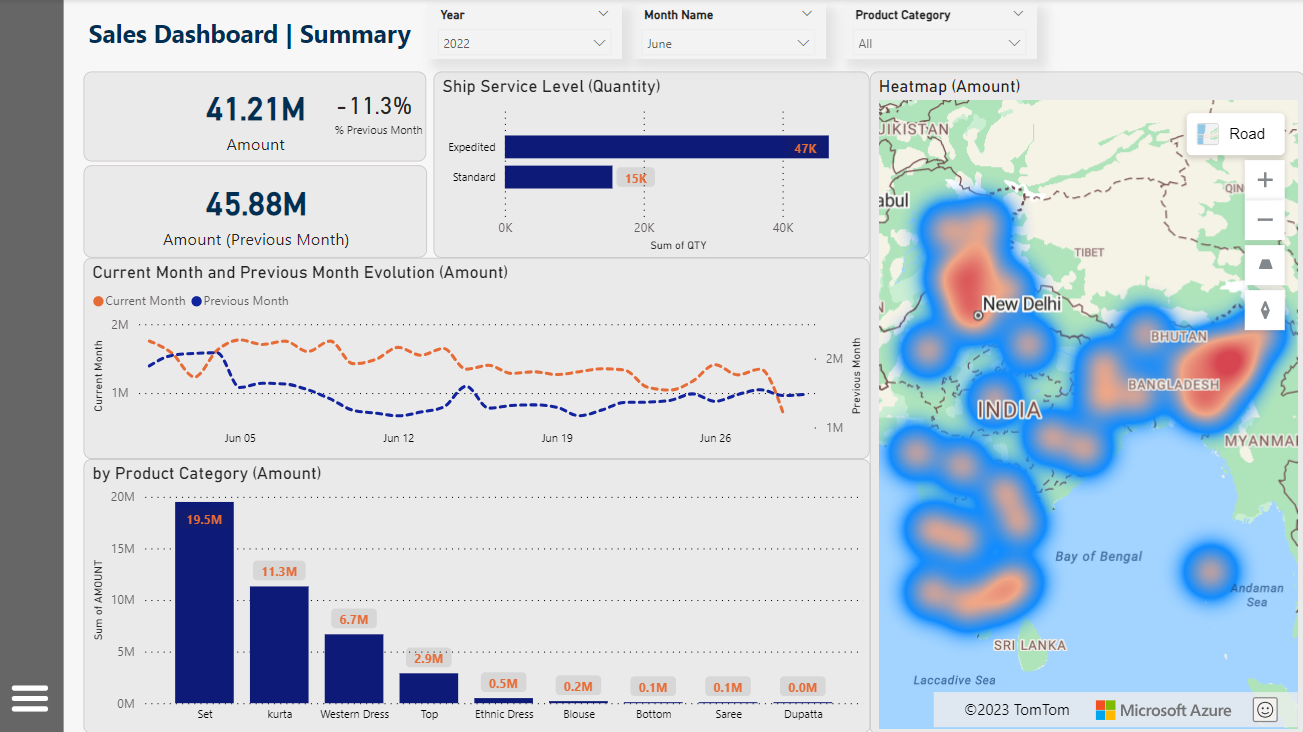
The end-to-end process reveals Amazon website sales data for the year 2022, sourced from Kaggle, widely regarded as the top repository in the realm of Data Science. This dataset focuses on a specific region in India, offering a captivating opportunity to break it down into segments and showcase the power of data processing and transformation using Python / SPARK. The experience is so intuitive.
To enhance the dataset’s quality, I integrated an Indian postal code API, addressing the issue of numerous empty or inaccurate data points within the dataset - its related in the following code transformation.
Technical solution

Requirements
To use this repo, you will need the following:
- Clone this repository to your local machine and upload the INTEGRATION_ECOMMERCE.ipynb.
- Download the assets from Kaggle and upload into the Databricks.
- Databricks: File -> “Upload data to DBFS”…
Notebook
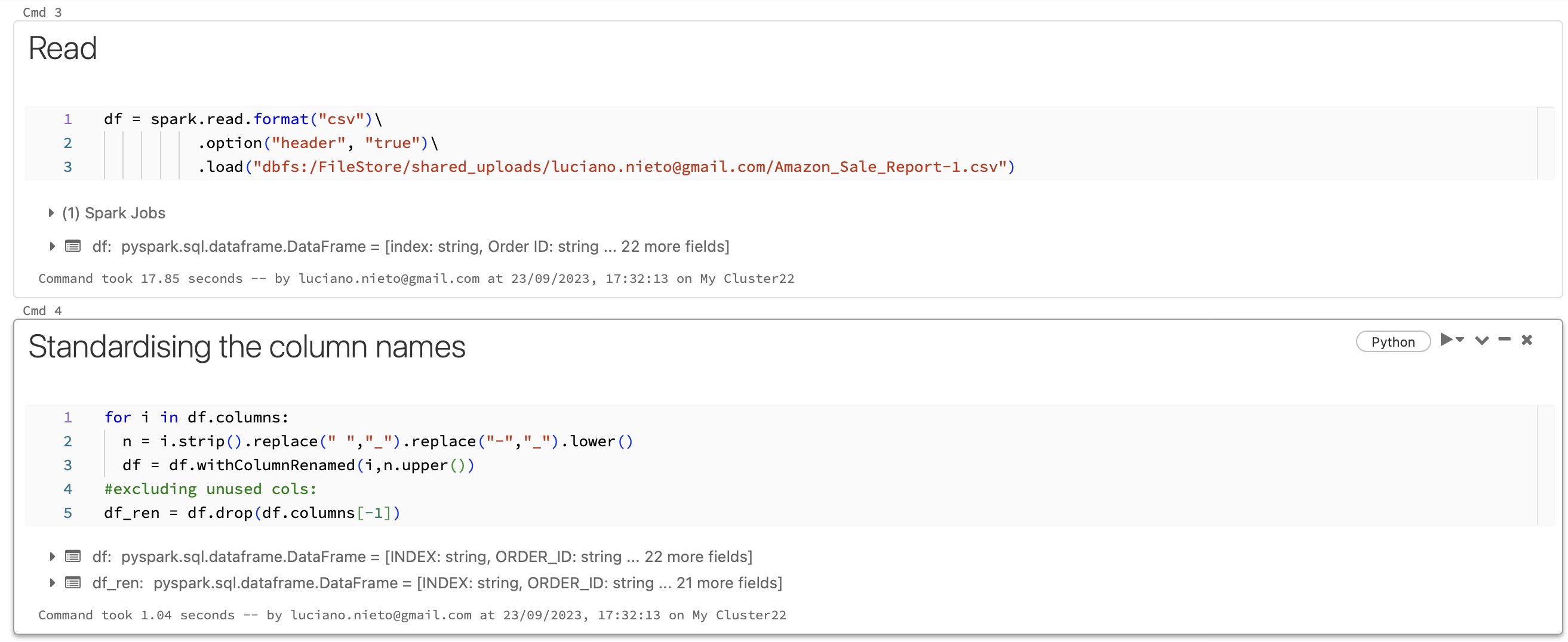
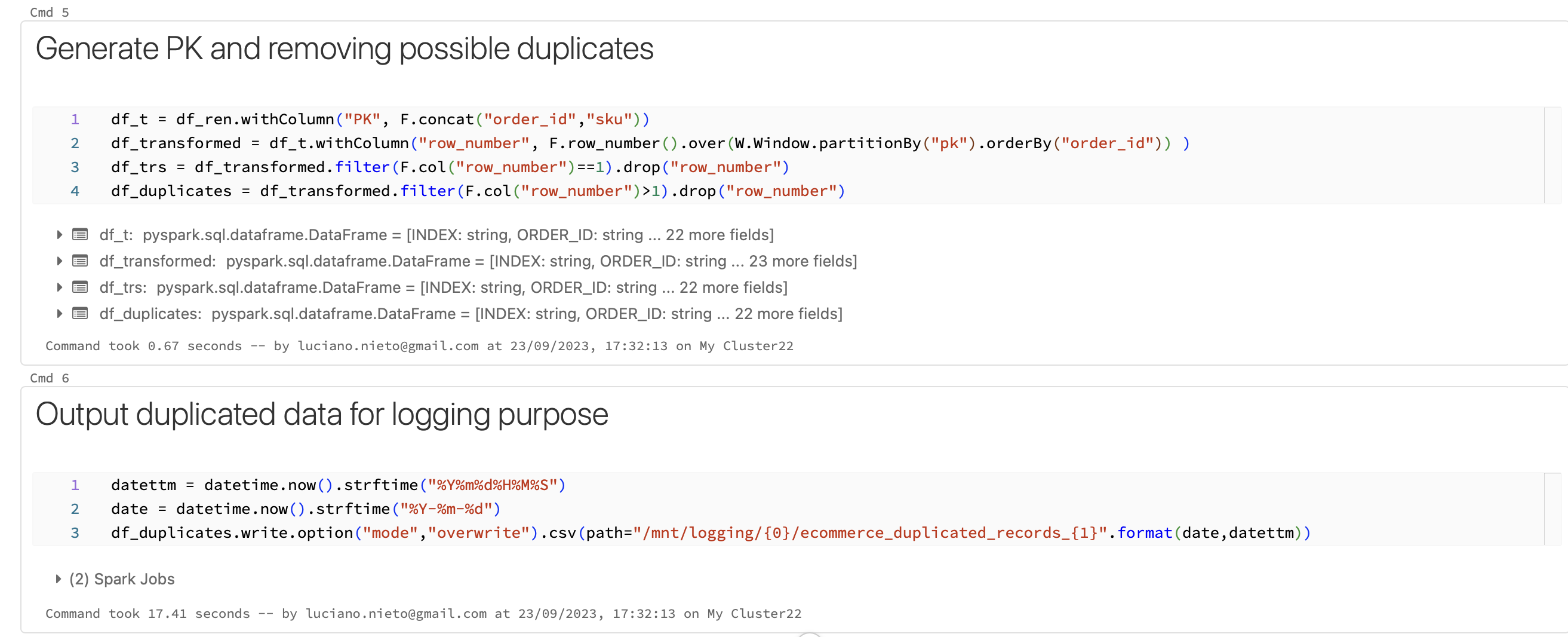
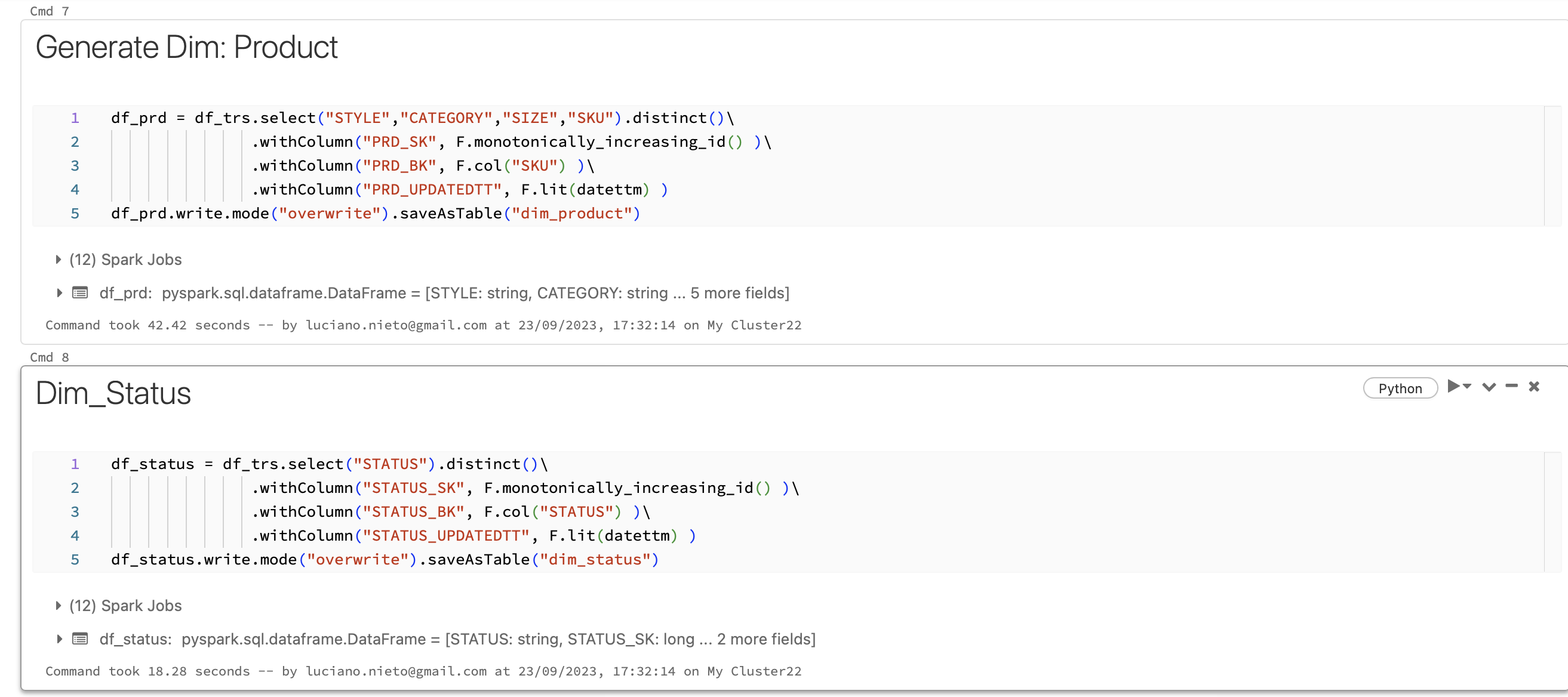
This is the notebook managed in Databricks:
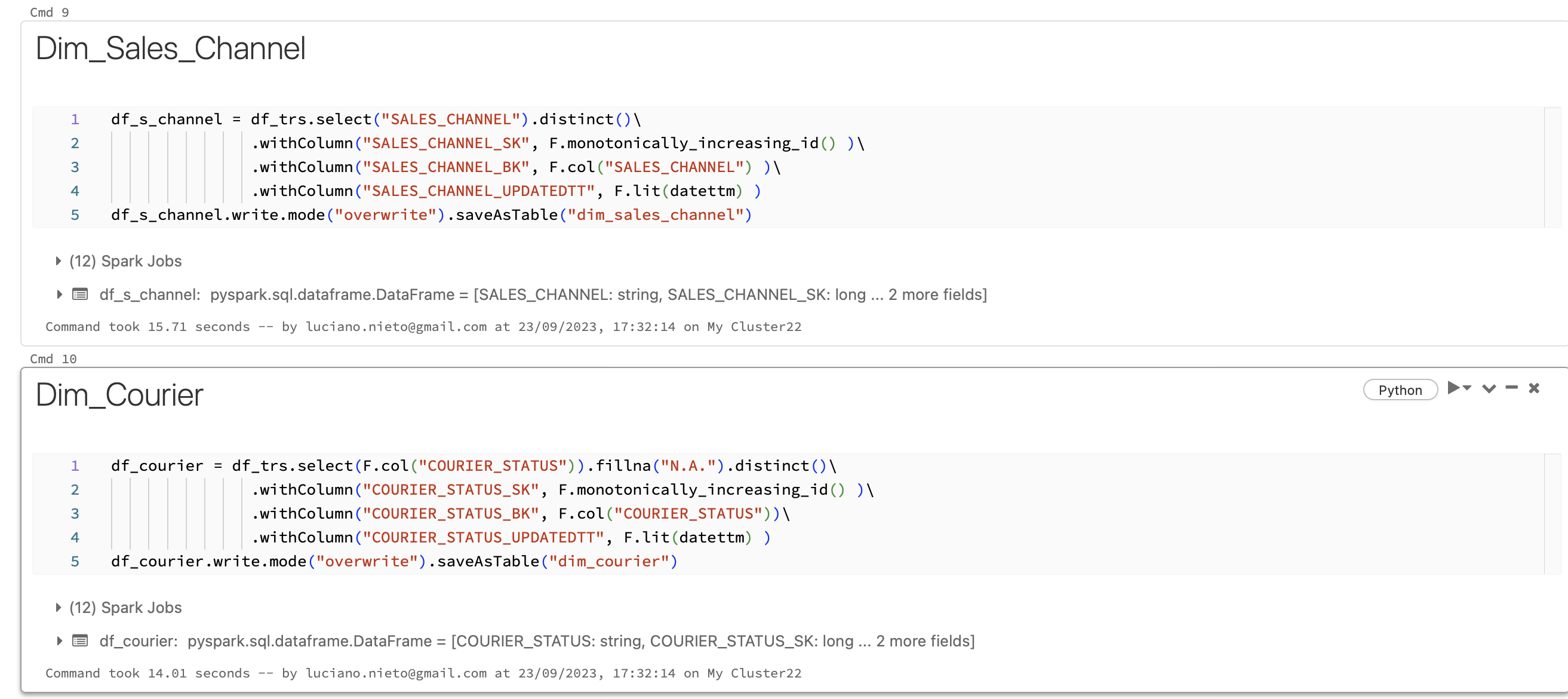
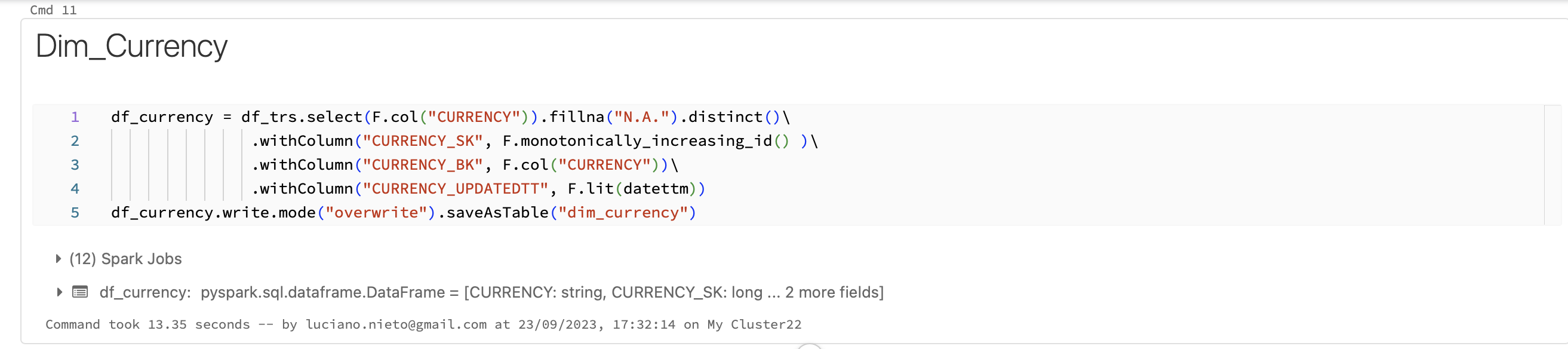
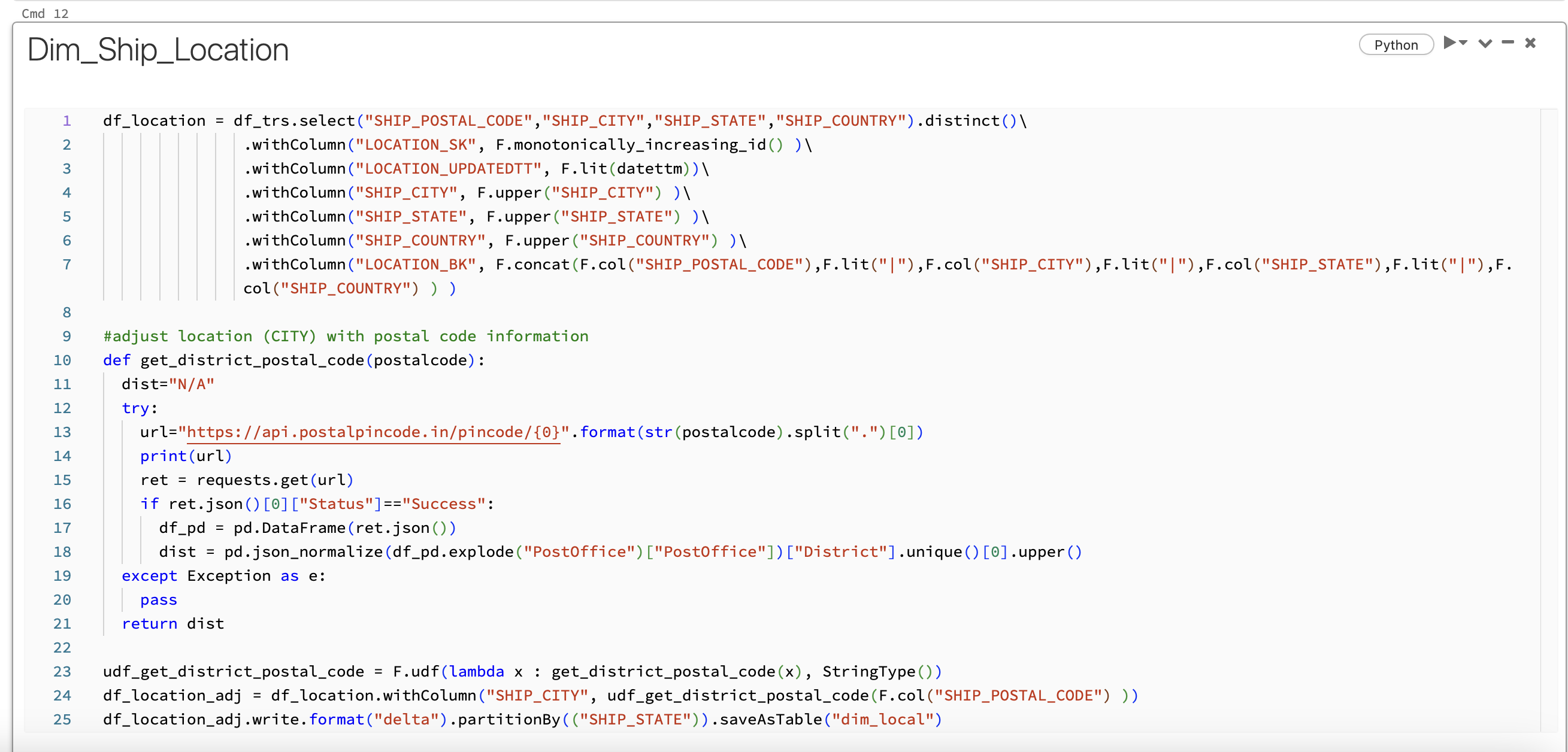
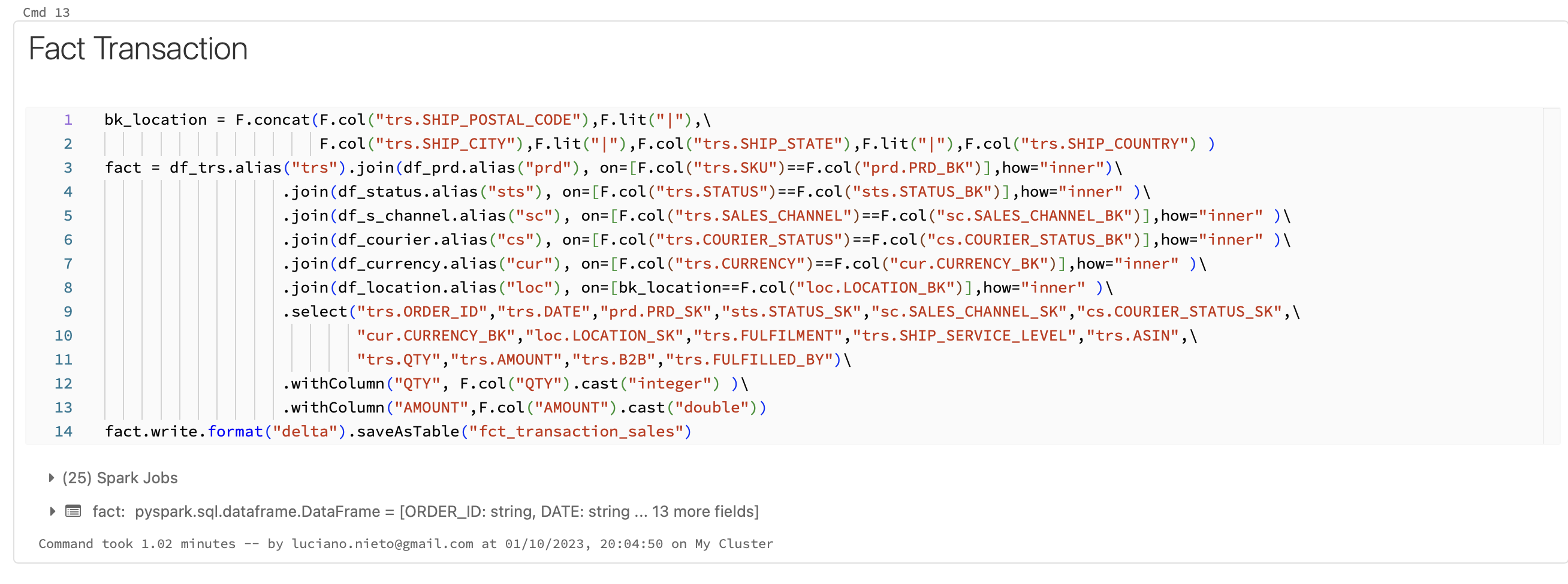
Modeling
The model in Power BI was developed with Star Schema approach.
Report
- URL here
The link becomes accessible only during the active trial period.
More
- GitHub Repo here.