Use Web Scraping to Get Data
I always heard about web scraping but I have no idea how or what will be the purpose of using it. That was really strange to me because in my projects I always used the corporate system as a source and didn’t use it in any project that I had worked on.
After a quick search on the internet, I found some interesting posts about it and I resolved to check it out. This is a quite simple line of code but shows the idea of how to navigate and how to work with web scraping.
One thing that we have to keep in mind is to read first the terms of conditions of the website that you’re accessing to complain with the rules.
Requirements
To use this repo, you will need the following:
- Clone this repository to your local machine.
- Install the library: BeautifulSoup
Acessing the website & understand the structure
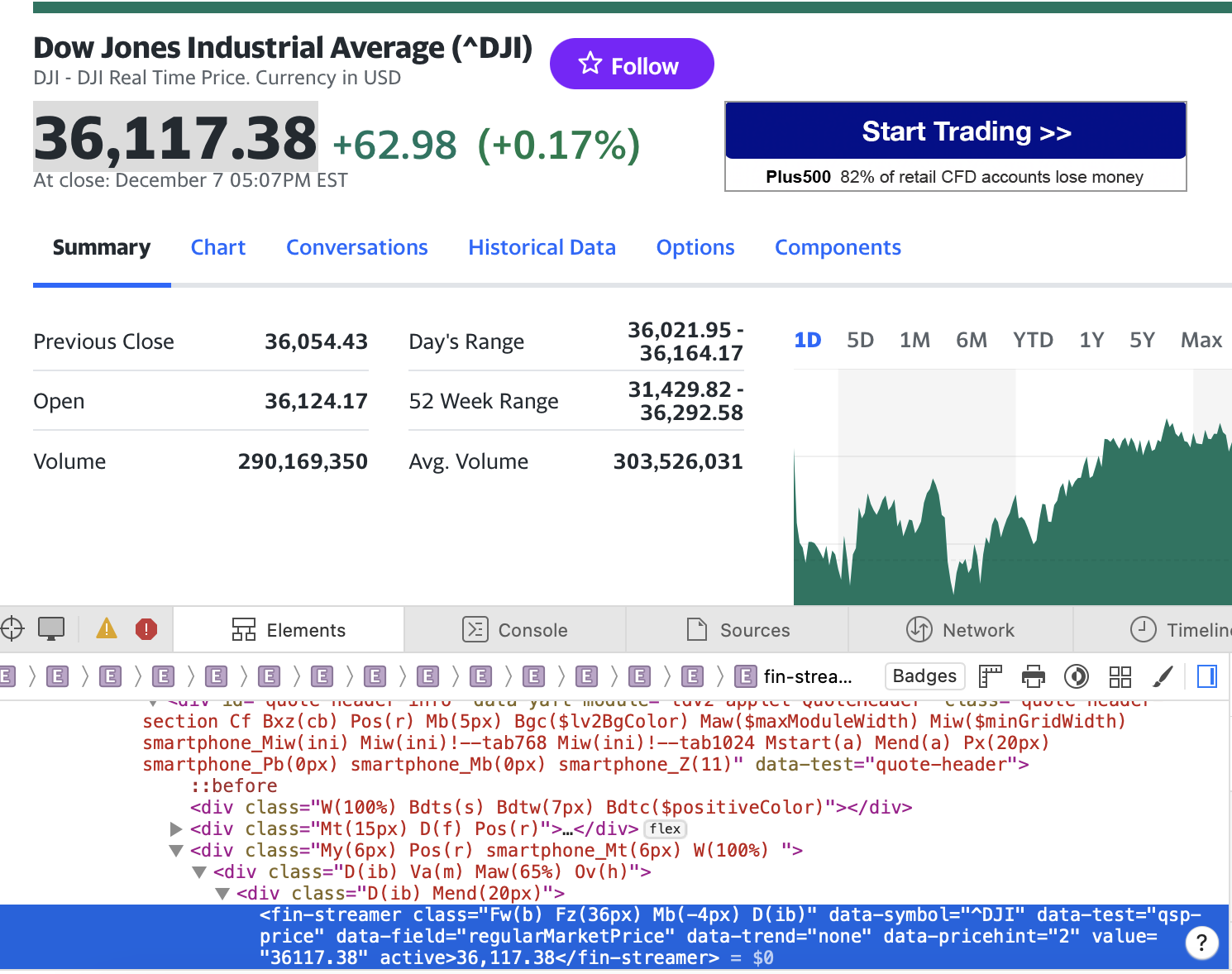
The first step is to access the website that you’re planning to get data and understand the HTML structure. I’ve used the structure based on websites that use HTML, and I’m not sure how it works with different types, such as Javascript.
Inspect:
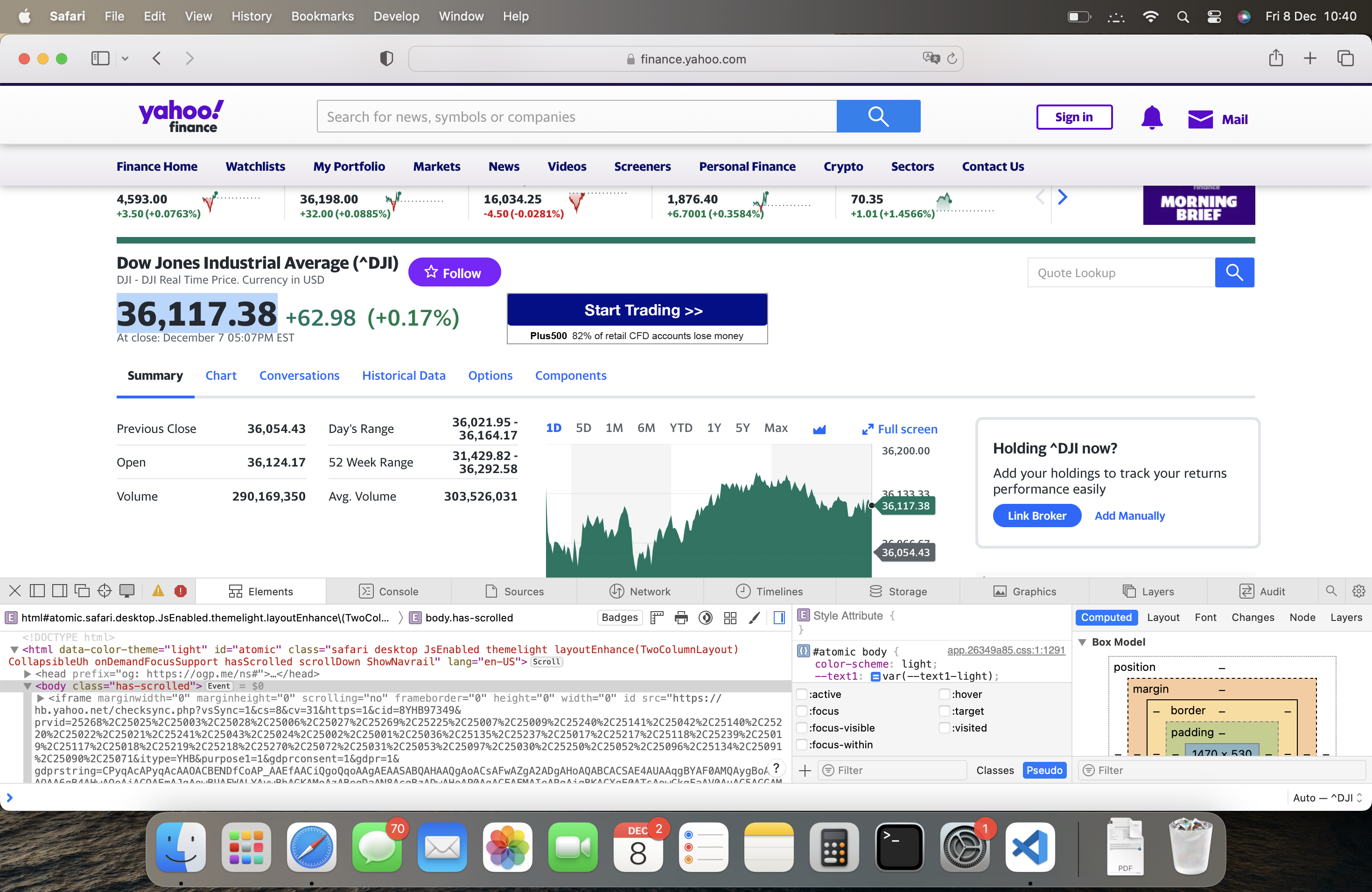
To understand it, you have to identify the level and pattern of the objects that the information is inserted into.
For this one:
- DIV/quote-header-info -> fin-streamer -> DIV/quote-market-notice.
Code & Result
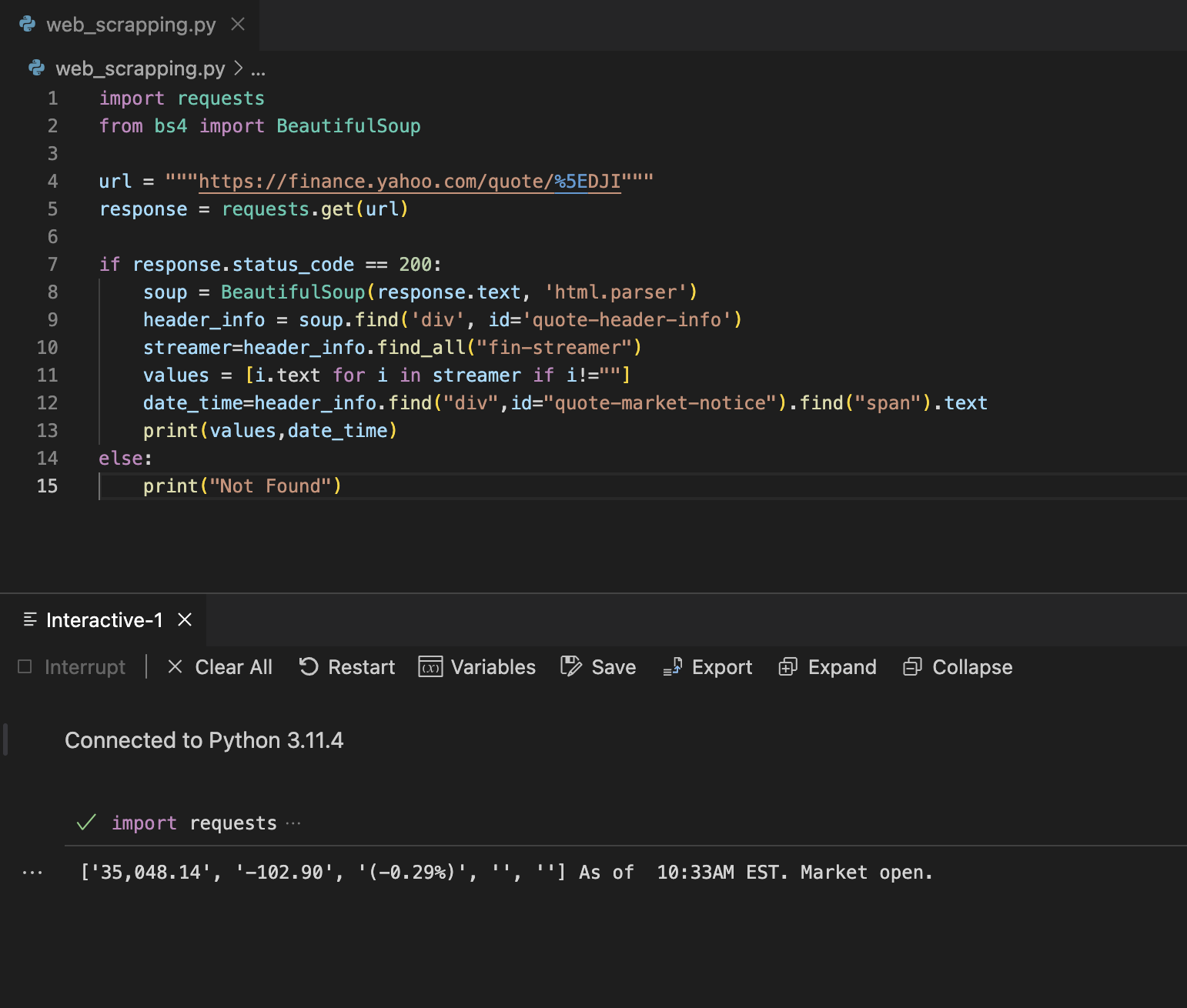
Some websites don’t allow to get data directly or updated - in this case there are a couple of hours of delay (of course it’s a piece of financial information that should be used for many robots - and isn’t paid).
More
- GitHub Repo here.